Risk Analysis and Management Strategies #
1. Introduction #
This document describes threats that could disrupt normal operations at SP and prevent the repository from fulfilling its mission for short or long periods of time. This document also describes risk-minimization strategies, system infrastructures, operating practices, and business relationships that SP uses to reduce the potential impact of these threats.
No analysis of threats can account for all possible threats and outcomes, nor should it. In general, it is not practical or efficient to focus on threats or sequences of threats that are extremely unlikely to happen or that require unreasonably expensive or debilitating counter-measures. SP has developed a typology of threats (section 4, below) by focusing on probable and manageable events in relation to the repository’s physical environment, technology infrastructure, repository content, personnel requirements, business relationships, and legal obligations. To develop this typology, SP examined risk management strategies practiced by several authorities in digital curation (see section 3).
2. Likelihood and Impact Assessment #
In order to assess the risks associated with individual threats and prioritize management strategies, SP estimated the likelihood and impact of each threat and plotted the combined result on a graph. Assessing threats in terms of likelihood and impact is a common strategy in disaster planning and is recommended by the Federal Emergency Management Agency (FEMA) and the National Institute of Standards and Technology (NIST).1 Here is an example of a graph:
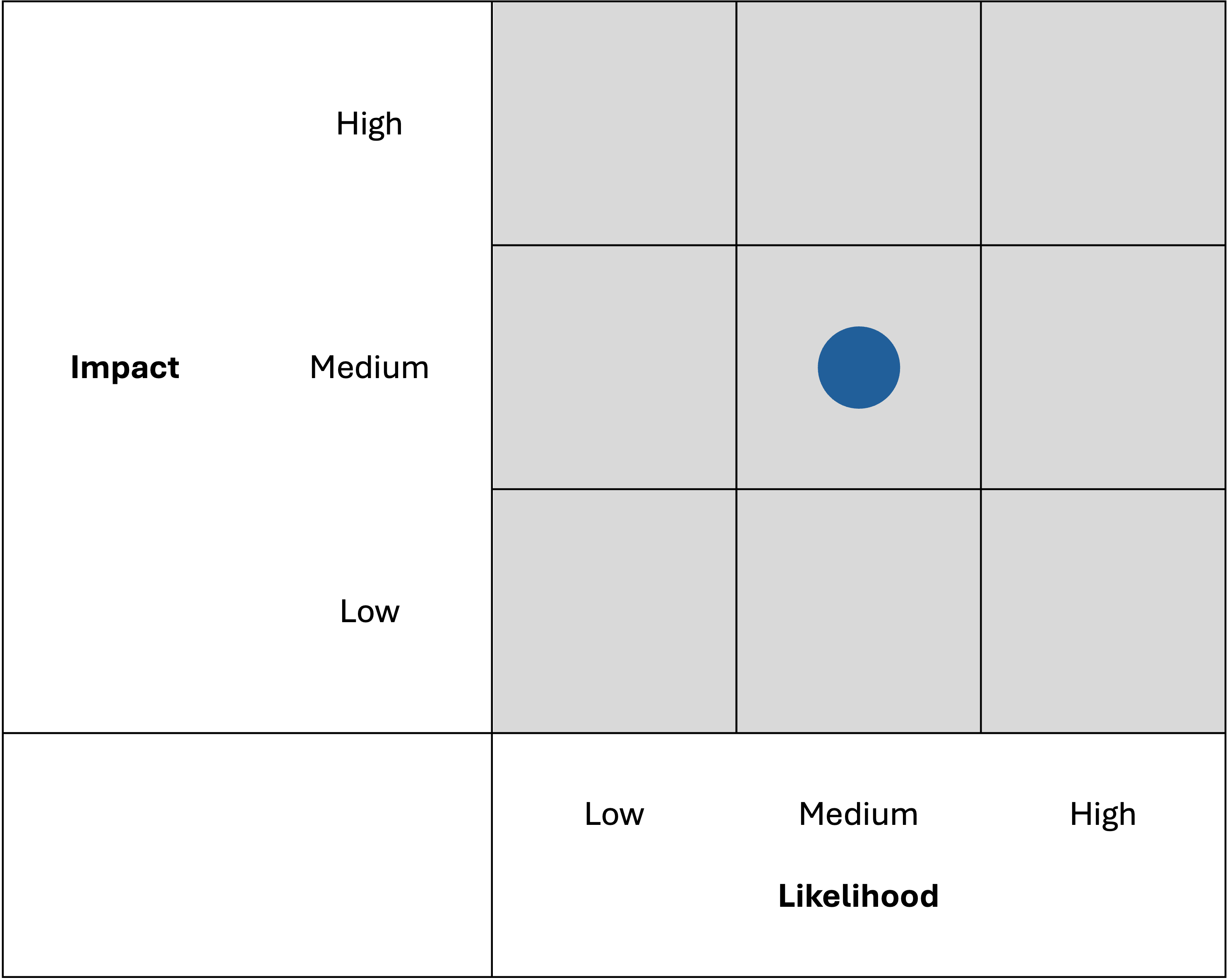
Likelihood and impact are represented on the graph as a blue marker. The position of each dot is necessarily speculative and serves as a guide for clarifying risks and planning management strategies. SP does not score the assessments at the present time.
Likelihood is an estimate of the frequency of a kind of event. SP divides the frequency of events into three periods:
- High: occurs every 0-2 years
- Medium: occurs every 3-7 years
- Low: occurs every 8+ years
These are rough estimates, and exceptional events are always possible.
Impact is an estimate of the effect that a threat may have on the repository’s content, services, and/or administration. SP divides impact into three categories of severity:
- High: Large-scale data loss in the storage array and/or prolonged service outage
- Medium: Small-scale, isolated data loss in the storage array and/or brief service outage
- Low: No data loss in the storage array and degraded system performance and/or disruption of repository administration, maintenance, or workflow
SP does not quantify these distinctions. In general, high-impact events may lead to widespread data loss and/or prevent the Designated Community from successfully accessing information or using one or more of the repository’s services for a prolonged duration. Medium-impact events may lead to some data loss and/or brief service outages. Some medium-impact events, whether small-scale data loss or brief service outages (or both), may be corrected before being discovered by the Designated Community. Low-impact events do not lead to data loss, but may degrade system performance or disrupt the administration of the repository in one way or another. For example, loss of staff does not lead to data loss, but can easily disrupt ongoing maintenance and interrupt projects. Please note that data loss and service outages have many causes and this document cannot describe all of them.
SP does not have an impact category for events that lead to widespread data loss in the storage array and the same loss simultaneously in the on- and off-site tape backup. At that point, SP would have to acquire the data from the original Providers and re-ingest the content.
3. Some Typologies of Threats #
Before starting its risk analysis, SP studied a number of risk analysis frameworks used by the digital curation community. Many risk analysis frameworks organize threats into a basic typology. This section outlines some typologies of threats found in the Consultative Committee on Space Data Systems’ (CCSDS) Audit and Certification of Trustworthy Digital Repositories criteria,2 the PLATTER framework developed by DigitaPreservationEurope (DPE),3 and the disaster recovery planning process used by HathiTrust.4
3.1 The CCSDS typology #
The Audit and Certification of Trustworthy Digital Repositories criteria expects that the repository “maintain[s] a systematic analysis of security risk factors associated with data, systems, personnel, and physical plant” (sec. 5.2.1). In their detailed explanation, the checklist recommends that the repository identify and manage risks related to:
- Hardware, software, communications equipment, facilities, and firewalls
- Physical environment
- Personnel, management, and administration
- Operations and service delivery
- Income, budget, reputation, and mandate
- Contractual and regulatory compliance
- Personnel knowledge and skills
- External threats and denial of service attacks
- Relationships with third parties
3.2 The PLATTER typology #
The PLATTER (Planning Tool for Trusted Electronic Repositories) checklist developed by DigitalPreservationEurope (DPE) encourages repositories to focus on “foreseeable disasters” in eight general categories (p. 37-39):
- Economic upheaval
- Political upheaval
- Loss of purpose/mandate
- Technological upheaval
- Environmental upheaval
- Loss of users and/or the arrival of competition
- Loss of educated key staff
- Breach of security
3.3. HathiTrust disaster planning typology #
- Hardware failure or obsolescence and data loss
- Network configuration errors
- Network security and external attacks
- Format obsolescence
- Core utility and/or building failure
- Software failure or obsolescence
- Operator error
- Physical security breach
- Natural or manmade disaster
- Media failure or obsolescence
4. Typology of Threats for SP #
The typologies listed in section 3 represent different perspectives on disaster, ranging from abstract, unpredictable threats (“political upheaval”) to tangible, expected threats (“software obsolescence”). Nevertheless, several common themes emerge, and SP has grouped threats into five general categories.
4.1 Economic, political, social, or legal threats #
- Loss of funding or institutional host
- Loss of staff
- Contractual liability
- Regulatory liability
4.2 Technology-related failures #
- Hardware failure and obsolescence
- Storage media failure (includes bit rot)
- Software failure and obsolescence
- File format-related obsolescence
- Loss of critical hardware or software support
4.3 Manmade threats #
- Operator error
- Sabotage by insider
- Cyber attack
- Physical security incident
4.4 Natural threats #
- Fire
- Flood
- Severe weather
- Earthquake
The threats listed here are based on threats recognized in the Emergency Plan of the City of Toronto, the Atmospheric Hazards – Ontario Region dataset published by Environment Canada and Emergency Management Ontario, and the Earthquake Zones in Eastern Canada background information published by Natural Resources Canada.5
4.5 Utility or environmental/building systems failure #
- Power failure
- Plumbing failure
- Server room cooling failure
- Heating, air conditioning, or air quality failure
5. Economic, Political, Social, or Legal Threats #
5.1. Loss of funding #
Dependencies #
SP depends on funding provided by the Ontario Council of University Libraries (OCUL). For that reason, SP is vulnerable to reductions in funding for higher education by governments, reductions in funding for libraries by individual universities, and reductions in funding for the OCUL consortium by member libraries. SP is also vulnerable to funding freezes by government, universities, and libraries. Cost increases that are not matched by funding increases are effectively reductions in funding.
Likelihood and impact assessment #
Loss of funding could span a range of probabilities and impacts. Full loss of funding (illustrated) is a low-likelihood, low- to high-impact event. Full loss of funding could force SP to suspend operations until the repository can establish a new source of funding or force it to activate its Succession Plan. A swift transition to a new source of funding minimizes the chance of a service outage. Partial loss of funding or freezes (not illustrated) are moderate-likelihood, low-impact events. Partial loss could slow or halt efforts to maintain existing collections, infrastructure, and services and delay the development of new collections and new services. SP expects that funding will fluctuate in relation to the financial health of governments and universities. In addition, funding could shrink if OCUL member libraries prefer to use content, infrastructure, or services offered by a competitor.
History #
Management strategy #
The current OCUL-UTL contract contains the funding agreement for SP. Under the terms of the OCUL-UTL contract, OCUL provides annual authorization for SP’s budget. Additional expenditures, either for staff or technology, are at the discretion of OCUL on a case-by-case basis.
SP remains competitive by providing extensive content and innovative services to OCUL member libraries at a relatively low cost.
5.2. Loss of institutional host #
Dependencies #
SP depends on office space, services, and technology infrastructure provided by the University of Toronto Libraries (UTL). In the event that UTL refused to renew or changed the terms of its support, SP could be forced to move its administration, systems, and data to a new building or institutional host.
Likelihood and impact assessment #
Loss of institutional host is a low-likelihood, low- to medium-impact event. Moving to a new host will disrupt the administration of the repository for a short time and may result in brief service outages. The impact will vary according to the nature of any problems encountered during the migration. In the event that a new institutional host is not immediately found, SP could be forced to suspend operations until the repository can identify a new host or be forced to activate its Succession Plan.
History #
SP has been hosted by the same institution since its inception.
Management strategy #
SP conducts regular reviews of its Succession Plan to ensure its ongoing utility, relevance, and operationalization. SP and OCUL will also monitor member support for continued repository operations and financial capacity to conduct operations. SP receives ongoing feedback about the repository from its Designated Community.
5.3. Loss of staff #
Dependencies #
SP depends on knowledgeable and skilled personnel to maintain the repository and satisfy the evolving needs and expectations of its Designated Community. SP also depends on experienced leaders who can manage projects, mentor personnel, and advocate on behalf of the repository. SP requires stable, typical, and ideally low rates of staff turnover in order to manage projects effectively and efficiently.
Likelihood and impact assessment #
Loss of staff is a high-likelihood, low-impact event. Loss of knowledgeable and skilled personnel is inevitable in the life of an organization, and therefore it is a high-likelihood event, but losses do not typically lead to service outages or data loss. The severity of the impact will depend on the individuals lost. Loss of staff at any level could affect the ability of SP to operate in an efficient and innovative manner. Loss of leadership could disrupt business relationships, disrupt administrative activities, and affect the reputation of the repository. The loss of a large number of staff could slow or stop efforts to maintain existing content, infrastructure, and services and delay the development of new content and new services. A temporary loss of staff could slow or stop administrative activities, project development, and ongoing maintenance.
Loss of staff due to a public health emergency, such as widespread illness, is a low-likelihood event. The impact of a public health emergency could vary from low to medium (and possibly high, not illustrated) based on the severity and scale of the emergency, the level of public preparedness, and the nature of the emergency response. SP may experience a significant disruption to its office environment or a loss of staff due to widespread illness, which could slow or stop administrative activities, project development, and ongoing maintenance. Depending on the geographic and temporal scale of the emergency, there is a risk of delays in addressing issues that require physical components and onsite access, such as hardware and storage media replacements, which could have a medium to high impact. SP’s strategy for minimizing the risk of hardware failure is outlined in 6.1.4.
History #
The COVID-19 pandemic response in Toronto began in March 2020 and included a series of lockdown and stay-at-home measures and a local state of emergency, which lasted until May 2022.6 During this period, access to SP offices, the UTL server room, and its off-site storage facility was severely restricted. Service was disrupted, but no data, databases, or applications were damaged or lost.
Management strategy #
SP uses well known hardware components and programming practices to minimize the risk of losing programmers and IT staff.
SP delegates responsibility for projects and repository administration to several people in order to reduce single points of failure.
SP uses SPOTDocs, a collaborative documentation portal, for knowledge management, project planning, and document sharing.
SP documents major changes to its organizational and technical infrastructure in its annual reports to OCUL Directors. These reports record the history of changes in ongoing and planned projects, contractual obligations, organizational structure, staffing levels, operating procedures, hardware, and software. OCUL preserves copies of these reports. In addition, OCUL preserves copies of minutes of meetings and budgets in order to record the history of key decisions made by staff. SP makes copies of its administrative and operational documents as a part of its regular Backup Plan.
The Organizational Chart identifies appropriate staff who can explain repository practices and workflows.
SP reduces the rate of staff turnover by offering its employees competitive compensation and benefits, clear and reasonable performance expectations, constructive and practical feedback, and opportunities for advancement and professional development.
In the event of a public health emergency, SP complies with emergency preparedness and response procedures designed by UTL and the University of Toronto. Staff will follow procedures outlined in UTL’s Emergency Procedures Manual and directives issued by the University of Toronto and government bodies.
When required, SP is able to implement a work-from-home policy for all employees and provide institutional and infrastructural support for remote work. Critical information, processes, and communications are accessible through online platforms. SP staff work closely with personnel from ITS to coordinate onsite access and hardware replacements.
For hygiene and sanitation, SP depends on facilities management provided by UTL and University of Toronto’s Facilities and Services department.
5.4. Contractual liability #
Dependencies #
SP operates according to the terms and conditions of several agreements in order to carry out its mission. Key agreements include those between OCUL and content Providers and between OCUL and UTL. It is critical that SP fulfill its contracted obligations.
Likelihood and impact assessment #
Contractual liability is a low-likelihood event. It is difficult to estimate the impact of contractual liability because the context and circumstances of any problem may vary widely. In some cases, contractual liability may lead to a temporary service outage while SP staff work to resolve the problem. In other cases, the impact may be strictly administrative or financial (not illustrated). Removal of content by a Provider would be a high-impact event (not illustrated).
History #
Management strategy for risks related to licensed materials #
When necessary, OCUL seeks legal counsel for decisions related to licensing agreements.
In all matters of ingest, data management, archival storage, dissemination, and repository administration, SP operates according to the terms of license agreements between OCUL and content Providers. These agreements describe usage rights in detail and provide SP with clear directions for managing ingest processes, recording administrative metadata, and implementing security and access controls.
OCUL members provide SP with lists of IP addresses and IP-address ranges in order to control access.
When required by the terms of the license, OCUL makes reasonable efforts to provide authorized users with appropriate notice of the terms and conditions of access. In general, OCUL members communicate terms and conditions to their respective users. SP works closely with OCUL members to manage access controls according to the relevant terms and conditions.
When required by the terms of the license, OCUL makes reasonable efforts to provide authorized users with appropriate notice of applicable intellectual property or other rights related to materials. In general, OCUL members communicate usage rights to their respective users. In many cases, article PDFs stored in the SP repository include a visible copyright statement.
When required, SP and OCUL will use reasonable efforts to protect the materials from any use that is not permitted under the license. In practice, these efforts may include terminating a user’s access to materials or terminating the access of the IP address(es) from which unauthorized use occurred.
Whenever possible, OCUL obtains from Providers a nonexclusive, royalty-free, perpetual license for materials. Whenever required under the terms of the license, OCUL and SP will ensure that access rules and copyright as stated in the license remain in place in perpetuity.
Whenever possible, the license agreements provide OCUL with a time-limited period (e.g. 30 days) to cure an alleged breach.
SP Management strategy for risks related to the OCUL-UTL service agreement #
The OCUL-UTL service agreement provides terms and conditions for service availability. SP works closely with ITS to ensure that the repository meets those terms and conditions.
The OCUL-UTL service agreement provides terms and conditions for network and system performance. SP works with ITS to ensure that its network topology meets the needs of the Designated Community. SP uses a variety of widely accepted, industry-standard techniques and tools to monitor the repository’s hardware platform. Systems administrators at SP and ITS receive information about system behaviour and usage from a number of custom-built scripts, a Nagios monitoring program, and monitoring functionality built into the hardware. These tools warn administrators about abnormal activity such as excessive processor loads and slow response times. In addition, staff monitor critical processes, such as ingest and data management, for malfunctions and suboptimal performance. SP receives ongoing feedback about system behaviour from its Designated Community. Feedback provides valuable information about response times, page loading, and overall system performance.
SP employs staff for client support and network troubleshooting, and they are available according to the schedule set out in the OCUL-UTL service agreement.
In order to detect unauthorized access, SP monitors usage patterns for abnormal behaviour that may signify a violation of SP’s access policies.
SP operates in a manner consistent with the terms and conditions of the Freedom of Information and Protection of Privacy Act (FIPPA).
The OCUL-UTL agreement contains terms and conditions for dispute resolution and indemnification.
The OCUL-UTL agreement contains terms and conditions for dispute resolution.
5.5. Regulatory liability #
Dependencies #
SP must design, implement, and administer the repository in a manner that is consistent with relevant provincial and federal laws.
Likelihood and impact assessment #
Regulatory liability is a low-likelihood event. It is difficult to estimate the impact of regulatory liability because the context and circumstances of any problem may vary widely. In some cases, regulatory liability may lead to a temporary service outage while SP staff work to resolve the problem. In other cases, the impact may be strictly administrative or financial (not illustrated).
History #
Management strategy #
SP staff work closely with OCUL members to ensure that SP operations are consistent with relevant provincial and federal laws. SP keeps a list of legislation that are clearly relevant to its preservation activities.
When necessary, SP and OCUL seek legal counsel for decisions related to regulatory compliance.
Licensing agreements between OCUL and content Providers are governed by and construed in accordance with the laws of the Province of Ontario.
The service agreement between OCUL and UTL is governed by and construed in accordance with the laws of the Province of Ontario and the federal laws of Canada applicable therein.
6. Technology-related threats #
6.1 Hardware failure #
Dependencies #
SP relies on the continuous, error-free operation of servers, a storage array, and workstations in order to carry out its mission. SP uses Dell servers and an EMC Isilon RAID storage array housed in UTL’s secure computing facility. In addition, the repository’s backup system depends on a tape storage unit. Hardware may fail due to spontaneous malfunctions, manufacturing defects, or improper operation. Points of failure include power supplies, fans, connectors, and (highly unlikely) chips and motherboard components.
Storage media failure due to mechanical failure, physical degradation, or magnetic failure is analyzed as a stand-alone topic in section 6.2.
Likelihood and impact assessment #
Hardware failure is a low-likelihood event. However, hardware failure can span a range of impacts depending on the components involved and the nature of the failure. The number of components and/or sites involved may affect the duration of any outage.
There is a risk that large-scale hardware migrations could cause temporary service outages and lead to data loss.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to hardware failure.
Management strategy #
SP staff work closely with personnel from ITS to monitor hardware health, perform routine maintenance, and install replacements or upgrades.
SP and ITS have a stock of surplus components for some hardware.
SP uses a variety of widely accepted, industry-standard techniques and tools to monitor the repository’s hardware platform. Systems administrators at SP and ITS receive information about system behaviour and usage from a number of custom-built scripts, a Nagios monitoring program, and monitoring functionality built into the hardware. These tools warn administrators about abnormal activity such as excessive processor loads and slow response times. In addition, staff monitor critical processes, such as ingest and data management, for malfunctions and suboptimal performance.
Feedback from the Designated Community is an important source of information about system behaviour and hardware performance. Representatives from the Designated Community sit on SP’s advisory committees, giving them a direct channel to the repository’s directors and systems administrators. Feedback from the Designated Community provides valuable information about response times, page loading, and overall system performance.
SP has a commitment of funding for regular hardware replacement and/or upgrade. Emergency or extraordinary expenditures for hardware are at OCUL’s discretion.
SP replaces hardware within a 5-year period (i.e. every 5 years or less) even if the hardware is functioning normally.
SP buys a 5-year warranty for hardware components when possible.
When hardware changes are indicated, SP staff collaborate with personnel from ITS to evaluate hardware alternatives and the timing of hardware changes on a cost-benefit basis. Evaluations vary in formality according to the circumstances. The most extensive assessments take place whenever large components, such as the repository’s servers or storage array network, require replacement. When necessary, systems administrators at SP and ITS consult vendors for additional information and advice. Staff take the cost of hardware and future maintenance into account.
Large-scale hardware migration is carried out by technicians from the hardware vendor in collaboration with systems administrators from SP and ITS. Staff test and evaluate new hardware in isolation before moving the repository to the new component(s). In addition to tests and checks carried out by automated monitoring programs, staff manually assess changes by examining samples of relevant content. Staff evaluate changes for their effect on the integrity and understandability of information, the speed and interoperability of the system, and the accessibility and usability of disseminated content. Whenever hardware changes involve migrating data, the repository performs checksum and file size tests to validate the integrity of information.
To support long-term infrastructure planning, SP has an inventory of hardware and software.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
6.2. Storage media failure that leads to data loss #
Dependencies #
Storage media failure refers to mechanical failure, physical degradation, or magnetic failure in disk drives that may lead to data corruption or loss. The failure of multiple drives in the RAID array may lead to data loss and cause a service outage until SP and ITS can restore the affected content from backup. Media failure can be considered a species of hardware failure (section 6.1), but it is analyzed here as a stand-alone topic because of the critical importance of media refreshment to the long-term preservation of digital information. SP depends on an EMC Isilon RAID storage array and a tape backup system. Storage and backup media is managed by ITS.
Likelihood and impact assessment #
Storage media failure that leads to data loss is a low-likelihood, medium- to high-impact. The impact of storage media failure varies according to the extent of the damage, the data affected, and the duration of any service outage.
Storage media may fail in a RAID array without causing data loss. For example, the failure of a single drive in the RAID array should not lead to data loss. However, a drive failure will compromise the array’s overall redundancy.
There is a risk that disk replacement and data copying operations could cause temporary service outages.
History #
Management strategy #
The repository uses an EMC Isilon RAID storage array network for disk redundancy.
The Isilon array has health-monitoring, diagnostic, and error-correction tools. The storage controllers will automatically report errors to ITS and SP staff. SP’s MarkLogic database performs consistency checks on bibliographic and preservation metadata.
SP uses a number of tools and procedures to detect bit corruption or loss. The repository uses widely accepted hashing techniques to generate digest values for new content and carries out regular, automated fixity checks on archived content. For each journal article, the repository generates and records MD5, SHA-1, and CRC32 values for each file associated with the article, including the bibliographic metadata. Digest values are stored in the preservation metadata, which is separate from the article’s files. SP also records file sizes at byte scale.
SP replaces storage media according to a predetermined schedule or whenever media exhibit performance problems. As a rule, SP refreshes its storage array media within a 5-year period (i.e. every 5 years or less) even if the drives are functioning normally and appear healthy. SP refreshes backup tapes annually to reduce the risk of degradation.
SP buys a 5-year warranty for hardware components when possible.
SP has a commitment of funding for regular storage media refreshment. Emergency or extraordinary expenditures for storage media are at OCUL’s discretion.
The procedures and tests involved in storage media change are very similar to those involved in hardware change. Please see 6.1.4, above, for details.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
6.3. Hardware obsolescence #
Dependencies #
SP relies on hardware components that work well with the repository’s applications, databases, and data and that interoperate well with associated components inside and outside the system.
Likelihood and impact assessment #
It is very difficult to assess the likelihood and impact of hardware obsolescence because it depends on the repository growth rate as well as developments in hardware, software, and user behaviour. It may affect diverse users in different ways. Degraded performance is the first sign of hardware obsolescence, but service outages should be expected. The impact could vary from low to medium (and possibly high, not illustrated) in relation to the components involved, the services affected, and the duration of any service outage. Hardware obsolescence is medium-likelihood in the context of repository growth and wider technological change.
There is a risk that large-scale hardware migrations could cause temporary service outages and lead to data corruption or loss.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to hardware obsolescence.
Management strategy #
SP’s strategy for minimizing the risk of hardware obsolescence is largely the same as its strategy for hardware failure. Please see 6.1.4, above, for details.
6.4. Software failure #
Dependencies #
SP depends on a variety of software components to carry out operations and fulfill its mission. The repository uses a combination of commercial, open-source, and custom-built software to ingest and transform content, manage backup, disseminate content, and deliver various services.
It is necessary for the repository to install new software or modify existing software as a part of normal operations. Software failure is typically confined to bugs or incompatibilities that appear during or after software changes. The CCSDS’ Audit and Certification of Trustworthy Digital Repositories checklist singles out security patches and firmware updates for special concern and states that they “are frequently responsible for upsetting alternative aspects of system functionality or performance” (sec. 5.1.1.4).7 Software failure could force SP to suspend operations until the affected systems can be thoroughly analyzed, repaired, and tested.
Likelihood and impact assessment #
Software failure is a high-likelihood, low- to high-impact event. It is a high-likelihood event because bugs, glitches, and incompatibilities are difficult to predict and eliminate. SP uses widely accepted, industry-standard procedures for testing and evaluating software changes, but small errors or conflicts sometimes escape testing. The impact may vary from low to high in relation to the systems affected, the duration of any service outage, and the extent of any data loss.
There is a risk that large-scale software migrations could cause temporary service outages and lead to data corruption or loss.
History #
Management strategy #
Software development, testing, and improvement is an ongoing process at SP. In general, there is no time when software is not subject to monitoring and evaluation.
SP uses a variety of current, widely accepted, industry-standard techniques and tools to monitor the repository’s applications. Systems administrators and programmers at SP receive information about system behaviour and usage from a number of custom-built scripts. Staff also receive information from monitoring functionality built into commercial software. These tools warn administrators about abnormal activity such as conflicts or slow processing times. The repository records errors in system logs and staff report software failures through a JIRA tracking system.
Feedback from the Designated Community provides valuable information about accessibility, usability, understandability, and holdings. SP receives ongoing feedback about application behaviour and interface design from its Designated Community.
SP staff evaluate all mandatory and optional security patches and software/firmware updates on a risk-benefit basis. SP applies all mandatory security patches and software/firmware updates. Staff may or may not apply optional patches or updates.
SP has a commitment of funding for regular software replacement and upgrade. SP has no fixed schedule for software replacement, but relies on information received from its Designated Community and from internal performance reports to indicate when software change is needed.
When software changes are indicated, SP staff collaborate with personnel from ITS to evaluate software alternatives and the timing of software changes on a cost-benefit basis.
SP tests and evaluates changes to software in isolated development environments to minimize the risk that changes will disrupt normal operations or cause data corruption or loss. Developers cannot write changes directly to the production server. In addition to automated tests and checks performed by programs, SP staff manually evaluate changes by examining samples of the relevant content. Staff evaluate changes for their effect on the integrity and understandability of information, the speed and efficiency of the system, and the accessibility and usability of disseminated information.
SP retains historical versions of software so that changes to critical processes can always be reversed. The repository’s backup process makes regular copies of the code versioning system.
To support long-term infrastructure planning, SP has an inventory of hardware and software.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
6.5. Software obsolescence #
Dependencies #
SP depends on software that interoperates well with hardware, data, and applications inside and outside the repository. In addition, dissemination software and web services must meet the evolving needs and emerging expectations of the repository’s Designated Community. SP uses a combination of commercial, open-source, and custom-built software to ingest and transform content, manage backup, disseminate content, and deliver various services.
File format obsolescence is a closely related problem. In this document, it is analyzed as a stand-alone topic in section 6.6.
Likelihood and impact assessment #
It is very difficult to assess the likelihood and impact of software obsolescence because it depends on the repository growth rate as well as developments in hardware, software, and user behaviour. It may affect diverse users in different ways. Degraded performance is the first sign of software obsolescence, but service outages should be expected. The impact could vary from low to medium (and possibly high, not illustrated) in relation to the services affected and the duration of any service outage. Software obsolescence is high-likelihood in the context of repository growth and wider technological change.
There is a risk that large-scale software migration could cause temporary service outages and lead to data corruption or loss.
While SP makes every effort to ensure that it offers web services that meet the needs and expectations of its Designated Community, the repository cannot guarantee that users have up-to-date and compatible software environments on their computers. For this reason, there is a risk that some users could experience software-related problems that the repository cannot control.
History #
The repository migrated its databases from Science Server to MarkLogic in 2008. This transition resulted in minimal interruption of service and no significant loss of data or understandability.
Management Strategy #
SP’s strategy for minimizing the risk of software obsolescence is largely the same as its strategy for software failure. Please see 6.4.4, above, for details.
To help users anticipate and manage certain software-related issues, SP adds notices to the SP Journals website. Previous notices have included: “Our search application is best viewed with newer browsers, including Firefox 3 and Internet Explorer 7 and 8. Older versions will work but with some loss of functionality.”8 A link to the repository’s contact form is available on the user interface.
6.6. File format-related obsolescence #
Dependencies #
SP ingests, preserves, and disseminates a variety of file formats in order to carry out its mission. While the repository is not dependent on or restricted to any particular format or group of formats, it aims to use well-known, widely accepted formats that support long-term preservation. Please see SP’s Preservation Implementation Plan for more information about the repository’s format policies.
Likelihood and impact assessment #
It is very difficult to assess the likelihood and impact of format-related obsolescence because it depends on developments in formats, software, and user behaviour. With respect to the formats that SP has preserved to date, the likelihood of obsolescence is generally low. If obsolescence occurs, the impact could vary from medium to high in relation to the duration of the problem. It can be a low-impact event (not illustrated) when SP moves proactively to migrate files from obsolete formats to accessible formats and users move swiftly to update any relevant software. The probability of a low-impact event increases when the formats in use, even though they have been superseded, remain widely known and well documented.
There is a risk that large-scale transformations could cause temporary service outages and lead to data corruption or loss.
While SP makes every effort to ensure that it preserves and disseminates formats that meet the needs and expectations of its Designated Community, the repository cannot guarantee that users have up-to-date and compatible software on their computers. For this reason, there is a risk that some users could experience format-related problems that the repository cannot control.
If format transformation is necessary, SP will give priority to maintaining the intellectual content contained in an individual object over preserving its appearance or a specific presentation. Consequently, some users may perceive that information has been altered or lost.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to format obsolescence. SP has not carried out any large-scale transformations.
Management strategy #
The repository’s first line of defense against format obsolescence is its ongoing efforts to preserve and disseminate formats that meet the needs and expectations of its Designated Community. To this end, SP monitors the digital curation field for broad trends and emerging standards (see Environmental Monitoring of Preservation Formats), carries out extensive usability testing, and solicits feedback from its Designated Community. In addition, SP works closely with OCUL member libraries to identify and manage format-related problems.
New formats introduced by Providers will alert SP to new practices in scholarly communication. SP is able to generate a log of formats archived to monitor the number of files in each format. A new trend in format usage will show up in the log.
The repository does not have a prescribed threshold or metric that would initiate format migration. The necessity and urgency of format migration will be evaluated on a case-by-case, cost-benefit basis.
To ensure the integrity of information during a large-scale transformation, SP would perform extensive testing, validation, and logging in an isolated development environment before initiating the transformation. After transformation, random samples of migrated content would be examined manually to assess their fidelity to the original. The migration and any related information would be recorded as an event in the preservation metadata for each object. SP would retain the original objects in its repository.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
6.7. Loss of critical hardware or software support #
Dependencies #
SP relies on hardware and software supplied by commercial vendors to fulfill its contracted obligations. In particular, the Dell servers, Pillar storage array, and MarkLogic database are central to the ongoing operation of the repository. Vendors could withdraw support if they discontinue a product, if their business strategies change, or if they encounter financial difficulties.
Likelihood and impact assessment #
Loss of support may not lead to service outages in the short-term, but it could force the repository to carry out substantial migrations. While disruptions may be limited to the repository’s administration and maintenance, the large-scale migration of data, databases, or applications could lead to service outages and data corruption or loss.
History #
SP migrated its databases from Science Server to MarkLogic in 2008. This transition resulted in minimal interruption of service and no significant loss of data or understandability.
Management strategy #
For servers, storage array, and databases, SP works with well known, commercially successful vendors who have large user bases.
SP employs a number of experienced systems administrators and programmers to oversee the repository’s technical operations. When hardware and software changes are indicated, they work closely with systems administrators at ITS to evaluate alternatives, timing, and expected outcomes. For more information about SP’s procedures for hardware and software change please see 6.1.4 and 6.4.4.
7. Manmade Threats #
7.1. Operator error #
Dependencies #
SP relies on cautious, skilled personnel to design systems, write software, perform routine maintenance, and correct errors. Minimizing or preventing operator error is crucial to protecting the long-term integrity of information in the repository and ensuring the reliability of the organization’s services.
Likelihood and impact assessment #
Operator error is a high-likelihood, low- to medium-impact event. People will inevitably make mistakes in the course of their work, and therefore operator error is a high-likelihood event. The impact will vary according to the systems and information involved. In general, it is unlikely that a single error will lead to widespread data loss or a prolonged service outage. However, efforts to fix operator error may lead to temporary service outages.
History #
Like any organization that manages complex information systems, SP experiences operator error from time to time. Errors are typically confined to a single AIP or a limited dataset such as an issue of a journal. As of January 1, 2012, SP has no record of widespread data loss or prolonged service outage related to operator error.
Management strategy #
SP has automated its critical processes in order to minimize the risk of operator error. Ingest, data management, archival storage, and dissemination are carried out by applications and use industry-standard error detection and quality control measures.
SP grants authorizations and administers access controls with the intention of maintaining a high level of security and stability. As described in the Security Plan, SP authorizes each staff member with limited access to system functionality based on his or her assigned duties. The Roles and Responsibilities document provides a general outline of the relationship between staff roles and specific duties. Only systems administrators can make changes to access controls.
Access to administrative-level system privileges is restricted to members of the repository’s system operations group. There is no root access to critical processes, servers, or the storage array under normal circumstances. Systems administrators have root access under exceptional circumstances.
Only systems administrators can write changes to the production servers or file system.
All ejournals volumes are mounted ‘read-only’ when they reach 2TB in size to reduce the risk of accidental tampering or deletion. Staff cannot write to ejournals volumes that have been mounted with a read-only restriction.
SP’s standard method of repairing errors in archived files or metadata is to request a corrected version of the article from the original Provider and re-ingest the complete package.
Regular fixity checks help to detect unauthorized changes to AIPs, after which SP staff can initiate recovery processes and revert the AIP to a known good state.
Only systems administrators have access to UTL’s secure computing facility. Only ITS can grant authorization to enter the facility.
Users retrieve disseminated information from a temporary directory or an HTML representation and not from the core storage directories.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
7.2. Sabotage by insider #
Dependencies #
In order to carry out its mission, SP provides its employees with appropriate and limited access to information and technologies that are subject to licenses, agreements, terms of service, access policies, and security controls. SP depends on the discretion, confidentiality, and lawful behaviour of its employees.
Likelihood and impact assessment #
Sabotage is a low-likelihood event. The impact may be medium or high because sabotage is a deliberately malicious act by an individual (or group) who knows, to a certain extent, how the system has been configured and protected. It may be difficult or time-consuming to identify the extent of the sabotage and repair the damage. Efforts to repair any damage may require temporary service outages.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to sabotage.
Management strategy #
SP reduces the risk of sabotage by offering its employees competitive compensation and benefits, clear and reasonable performance expectations, constructive and practical feedback, opportunities for advancement and professional development, and confidential mechanisms for dispute resolution.
All SP staff sign confidentiality agreements as a condition of employment with UTL.
SP’s strategy for minimizing unauthorized access to the repository is largely the same as its strategy for operator error. Please see 7.1, above, for details.
7.3. Cyberattack #
Dependencies #
SP relies on the continuous, error-free operation of its technology infrastructure and on the authenticity and integrity of data to carry out its mission and fulfill its contracted obligations. SP is committed to ensuring that its Designated Community can access authentic information in a safe and efficient manner. SP must have security controls that minimize violations of its access policies and licenses.
Likelihood and impact assessment #
SP expects that cyber attacks will occur often, though the impact will vary considerably in relation to the nature of the attack. On the one hand, some cyber attacks will have little (or no) effect on data or services. These attacks include programs designed to use SP as a platform or proxy for attacks on other targets. On the other hand, some attacks will affect service in obvious ways, either by impairing performance, causing service outages, or by damaging data. These attacks include automated content harvesting, denial-of-service attacks, and purely destructive attacks. Efforts to close the vulnerability, repair the affected components, and restore data could lead to temporary service outages.
History #
Management strategy #
SP systems administrators work closely with ITS personnel to minimize the risks associated with cyber attack. Both SP and ITS use current, widely accepted, industry-standard procedures to reduce vulnerability and respond to attacks. SP and ITS use a variety of techniques and tools to monitor the repository’s hardware and software. Systems administrators receive information about system behaviour and usage from a number of custom-built scripts, a Nagios monitoring program, an endpoint protection program, malware and virus detection programs, and ransomware protection and monitoring functionality built into hardware. These tools warn administrators about abnormal activity such as excessive processor loads and slow response times. In addition, staff monitor critical processes, such as ingest and data management, for malfunctions and suboptimal performance.
SP and ITS staff evaluate all mandatory and optional security patches and software/firmware updates on a risk-benefit basis. SP applies all mandatory security patches and software/firmware updates. Staff may or may not apply optional patches or updates.
SP, UTL ITS, and central IT have network protection mechanisms in place. These mechanisms include firewalls, proxies, packet filtering routers, intrusion detection systems, and malware and virus detection programs.
All ejournals volumes are mounted ‘read-only’ when they reach 2TB in size to reduce the risk of tampering or deletion.
Regular fixity checks help to detect unauthorized changes to AIPs, after which SP staff can initiate recovery processes and revert the AIP to a known good state.
SP does not limit bandwidth or data transfer volume for users unless there is a clear breach of security or terms of service. Pre-defined limits (caps) can sometimes degrade service for legitimate users. SP and ITS monitor system performance and usage in order to identify and block IP addresses that appear to be harvesting content.
Access to licensed content is enforced through the use of an entitlements module within the Scholars Portal system, which tracks what materials are to be made available through the end-user interface.
Users retrieve disseminated information from a temporary directory or an HTML representation and not from the core storage directories.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
7.4. Physical security incident #
Dependencies #
SP depends on physical security in order to protect its staff and safeguard the long-term authenticity and integrity of its data, databases, applications, and administrative documents. SP relies on security controls provides by UTL and ITS.
Likelihood and impact assessment #
Physical security incidents in connection with the SP and ITS offices and server room are low-likelihood events, though the impact may vary in relation to the staff involved and the systems affected. Incidents in connection with other areas of the Robarts Library complex are medium-likelihood, low-impact events (not illustrated).
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to physical security incidents. UTL’s Joint Health & Safety Committee keeps a record of security incidents in the larger Robarts Library complex. Incidents appear to be medium- to high-likelihood events.
SP Management strategy #
Physical security for SP is managed by UTL and ITS.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
ITS Management Strategy #
ITS coordinates physical security and access control for UTL’s secure computing facility. Only ITS can grant authorization to enter the facility, and access is restricted to authorized personnel.
UTL Management Strategy #
UTL coordinates physical security and access control for SP’s administrative offices. Entry to SP’s administrative office is controlled by electronic locks at all hours, and access is restricted to staff who work on the floor.
Access control gates are installed at all main entrances to Robarts Library and require staff, students, faculty, and registered visitors to swipe a valid TCard to enter the building. Security personnel are on duty in the Robarts Library building 24 hours a day.
Access to SP’s off-site storage facility for backup copies is restricted to authorized personnel at all hours.
8. Natural threats #
8.1. Fire #
Dependencies #
SP’s administrative offices and systems are located in a large building complex and are vulnerable to fire. SP depends on fire detection and suppression systems provided by UTL and the University of Toronto’s Fire Prevention unit.
Likelihood and impact assessment #
Fire is a low-likelihood event. The impact of a fire will vary according to the personnel and systems affected. Prolonged service outages are possible. Even if there is no evident damage to SP’s systems, a fire could force ITS to shut down service in order to permit assessment and repair of the facility. A fire elsewhere in the building or on the campus could affect network cables that deliver the repository’s information to the internet, effectively causing a service outage for a period of time. A fire in the surrounding region could affect electrical power for short or long periods of time (see 9.1 for information about electrical failure). A fire that prevents staff from carrying out their duties (e.g. staff cannot travel to the office) will likely be a temporary, low-impact event.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to fire.
SP Management strategy #
SP complies with emergency preparedness and response procedures designed by UTL and the University of Toronto’s Fire Prevention unit. In the event of evacuation, staff will follow procedures outlined in UTL’s Emergency Procedures Manual. When required, SP is able to implement a work-from-home policy for all employees and provide institutional and infrastructural support for remote work. Critical information, processes, and communications are accessible through online platforms.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
ITS Management Strategy #
Fire suppression in UTL’s secure computing facility is based on ceiling-mounted smoke detectors throughout the room in combination with hand-held chemical extinguishers.
UTL Management Strategy #
UTL has fire detection and suppression systems throughout Robarts Library.
8.2. Flood #
For plumbing failure in Robarts Library, see 9.2 below.
Dependencies #
In order to ensure the long-term preservation of content and the reliable and efficient dissemination of information to its Designated Community, SP relies on stable environmental conditions in its offices, the UTL server room, and its off-site storage facility. In addition, SP depends on stable, continuous electrical power.
Likelihood and impact assessment #
Flooding due to rain, snowmelt, or utility failure is a medium-likelihood event in Toronto and/or the surrounding area. The impact will vary according to the location and severity of the flood. There is little risk of physical damage to SP because the repository and its technology infrastructure are located on the seventh floor of a large building complex. However, flooding in the basement of the building could affect network cables that carry information from the repository to the internet. Flooding that causes extended electrical failures could lead to service outages (see 9.1, below, for analysis of electrical failure). For these reasons, the impact of flooding may be high (not illustrated). The likelihood of high-impact events is low. Flooding that prevents staff from carrying out their duties (e.g. staff cannot travel to the office) will likely be a temporary, low-impact event.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to flood.
Management Strategy #
SP complies with emergency preparedness and response procedures designed by UTL and the University of Toronto. In the event of evacuation, staff will follow procedures outlined in UTL’s Emergency Procedures Manual. When required, SP is able to implement a work-from-home policy for all employees and provide institutional and infrastructural support for remote work. Critical information, processes, and communications are accessible through online platforms.
For local water problems, SP depends on facilities management provided by UTL and University of Toronto’s Facilities and Services department.
SP is located on the seventh floor of Robarts Library, effectively isolating its offices and technology infrastructure from flooding, groundwater problems, watermain failures, and sewage problems.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
8.3. Severe weather (blizzard, thunderstorm, tornado) #
Dependencies #
SP depends on safe and typical weather conditions in order to carry out day-to-day operations, safeguard archival storage, and disseminate information to its Designated Community.
Likelihood and impact assessment #
Severe weather is a high-likelihood, low- to medium-impact event. Tropical storms, tornadoes, severe thunderstorms, heavily rainfall, heavy snowfall, and other extreme weather conditions have occurred in Toronto and/or the surrounding region.9 The chief risk to SP is from weather events that cause extended power failures. While the repository has an Uninterruptible Power Supply (UPS) for short-term operation of its storage array and servers, it does not have a mirror site. Prolonged power failures could lead to service outages. For that reason, severe weather can be a high-impact event (not illustrated). The likelihood of high-impact events is low. Severe weather that prevents staff from carrying out their duties (e.g. staff cannot travel to the office) will likely be a temporary, low-impact event.
History #
Inclement weather sometimes forces the University of Toronto to close for a short period of time, typically for one day. Unless the weather causes a prolonged power failure, the closure has no impact on archival storage or dissemination.
Management strategy #
SP complies with emergency preparedness and response procedures designed by UTL and the University of Toronto. In the event of evacuation, staff will follow procedures outlined in UTL’s Emergency Procedures Manual. When required, SP is able to implement a work-from-home policy for all employees and provide institutional and infrastructural support for remote work. Critical information, processes, and communications are accessible through online platforms.
The Robarts Library building is a large, thick-walled, reinforced concrete structure. UTL’s server room is located near the core of the building, away from the exterior walls and windows.
SP depends on power infrastructure and facilities management provided by UTL and the University of Toronto’s Facilities and Services department. See section 9.1, below, for details about the SP’s management strategy for electricity-related problems.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
8.4. Earthquake #
Dependencies #
In order to ensure the long-term preservation of content and the reliable and efficient dissemination of information to its Designated Community, SP relies on stable conditions in its offices, the UTL server room, and its off-site storage facility. In addition, SP depends on stable, continuous electrical power.
Likelihood and impact assessment #
Earthquake is a high-likelihood, low-impact event in the Southern Great Lakes Seismic Zone, which includes Toronto. “This region has a low to moderate level of seismicity when compared to the more active seismic zones to the east, along the Ottawa River and in Quebec. Over the past 30 years, on average, 2 to 3 magnitude 2.5 or larger earthquakes have been recorded in the southern Great Lakes region. By comparison, over the same time period, the smaller region of Western Quebec experienced 15 magnitude 2.5 or greater earthquakes per year. Three moderate sized (magnitude 5) events have occurred in the 250 years of European settlement of this region, all of them in the United States [. . .]. All three of these earthquakes were widely felt in southern Ontario but caused no damage.”10
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to earthquakes.
Management strategy #
SP complies with emergency preparedness and response procedures designed by UTL and the University of Toronto. In the event of evacuation, staff will follow procedures outlined in UTL’s Emergency Procedures Manual.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
9. Utility or Environmental/Building Systems Failure #
9.1. Electrical failure #
Dependencies #
SP requires continuous, stable electrical power at Robarts Library to maintain its collections, run various services, and disseminate information to its Designated Community. SP depends on electrical infrastructure within the building and on the electrical utilities that serve Toronto and southern Ontario. In addition, the continuity and stability of electrical power at SP’s off-site storage facility is important for maintaining environmental conditions and security systems.
Likelihood and impact assessment #
Electrical failure is a high-likelihood, low- to medium-event. The impact will vary according to the duration of the power failure. The uninterruptible power supply (UPS) can keep the repository’s storage array and servers running for a short period of time. Since the repository does not have a mirror site, extended electrical problems could lead to service outages and limited onsite access. Prolonged outages are low-likelihood (not illustrated).
Power spikes due to lightning strikes or utility irregularities (not illustrated) are a species of electrical failure and could damage the repository’s hardware, software, and data. These are low-likelihood events.
History #
During the northeast blackout in August 2003, which disabled electrical power at University of Toronto for approximately 12 hours,11 the repository’s servers and storage arrays shut down automatically when the UPS ran out. Service was disrupted, but no data, databases, or applications were damaged or lost.
SP Management strategy #
SP complies with emergency preparedness and response procedures designed by UTL and the University of Toronto. In the event of evacuation, staff will follow procedures outlined in UTL’s Emergency Procedures Manual.
Electricity and power infrastructure for SP is managed by ITS and UTL in conjunction with the University of Toronto’s Facilities and Services department.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
ITS Management strategy #
ITS maintains an uninterruptible power supply for the repository’s storage array and servers. The UPS provides continuous power in the case of short electrical outages. If an electrical failure lasts longer than the battery life of the UPS, SP and UTL ITS staff will initiate a controlled shutdown of the systems.
Electricity for the repository’s servers and storage passes through a power conditioner and protection circuit that ensures stable, clean power.
UTL Management strategy #
UTL has an “auxiliary power source that will provide adequate lighting for safe evacuation.”12
9.2. Plumbing failure #
Dependencies #
In order to ensure the long-term preservation of content and the efficient and timely dissemination of information to its Designated Community, SP relies on stable environmental conditions in its offices, the UTL server room, and its off-site storage facility.
Likelihood and impact assessment #
Plumbing failure that affects SP is a low-likelihood event, but the impact on will vary from low to medium depending on the systems involved and personnel affected. Water leaks that contact electrical devices are a serious threat to human safety, and therefore flooding could force SP and ITS to shut down systems until the situation can be evaluated and resolved. The worst-case scenario is water flooding into the UTL server room from the floors above. Plumbing failures in other parts of the building could affect electrical power and/or network cables that carry the repository’s content to the internet.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to plumbing failure.
SP Management strategy #
SP depends on facilities management provided by UTL and the University of Toronto’s Facilities and Services department. ITS monitor and manages conditions in UTL’s server room.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
ITS Management Strategy #
9.3. Server room cooling failure #
Cooling of servers and storage arrays is important for the integrity of data, databases, and applications. Server room cooling depends on electrical power for operation. Please see 9.1, above, for SP’s risk analysis and management strategies for electrical failure.
Dependencies #
SP depends on stable environmental conditions in its administrative offices and its off-site storage facility in order to carry out its mission. Environmental systems in Robarts Library and SP’s off-site facility are dependent on continuous electrical power.
Likelihood and impact assessment #
Heating, air conditioning, and air quality failures are high-likelihood events because they are dependent on electrical power. Any power failure in the Robarts Library building or the surrounding region could shut down environmental systems in the SP office. Local or regional power failures may shut down systems at SP’s off-site facility. Temporary environmental problems that affect human comfort may disrupt the administration of the repository but should not lead to service outages or data loss.
History #
As of January 1, 2012, SP has no record of service outages, data loss, or management disruptions related to heating, air conditioning, or air quality failure.
Management strategy #
SP depends on facilities management provided by UTL and the University of Toronto’s Facilities and Services department. ITS monitors and manages environment conditions in UTL’s server room.
SP carries out regular backup of data, databases, and applications according to its Backup Plan. These backups are intended to serve as the basis for restoration of SP materials in the event of data corruption or loss.
References #
- FEMA. Emergency Management Guide for Business & Industry. FEMA 141. Federal Emergency Management Agency, October 1993. https://www.fema.gov/pdf/library/bizindst.pdf accessed 27 June 2022; National Institute of Standards and Technology. Guide for Conducting Risk Assessments – Initial Public Draft. NIST Special Publication 800-30 Rev. 1, July 2002. http://csrc.nist.gov/publications/drafts/800-30-rev1/SP800-30-Rev1-ipd.pdf accessed 27 September 2011.
- Consultative Committee on Space Data Systems. Audit and Certification of Trustworthy Digital Repositories – Recommended Practice – CCSDS 652.0-M-1. Consultative Committee on Space Data Systems, September 2011. http://public.ccsds.org/publications/archive/652x0m1.pdf accessed 21 September 2011.
- DigitalPreservationEurope. DPE Repository Planning Checklist and Guidance DPE D3.2. DigitalPreservationEurope, April 2008. http://www.digitalpreservationeurope.eu/platter.pdf accessed 21 September 2011.
- Shallcross, Michael. The Hathi Trust is a Solution: The Foundations of a Disaster Recovery Plan for the Shared Digital Repository. Hathi Trust, 2009. https://web.archive.org/web/20211117165453/https://www.hathitrust.org/technical_reports/HathiTrust_DisasterRecovery.pdf accessed 21 August 2024.
- Office of Emergency Management. Emergency Plan. City of Toronto, December 2021.https://www.toronto.ca/wp-content/uploads/2022/01/9593-Emergency-Plan-2021-2022-01-11-FINAL.pdf accessed 27 June 2022; Environment Canada. Atmospheric Hazards – Ontario Region. Environment Canada and Emergency Management Ontario, 22 December 2010. https://web.archive.org/web/20120120200739/http://ontario.hazards.ca/intro-e.html accessed 27 June 2022; Natural Resources Canada. “Background on Earthquakes in Eastern Canada.” Earthquake Zones in Eastern Canada. Natural Resources Canada, 2011. http://earthquakescanada.nrcan.gc.ca/zones/eastcan-eng.php#SGLSZ. Accessed 8 February 2012.
- Wikipedia contributors. COVID-19 pandemic in Toronto. Wikipedia, The Free Encyclopedia, 11 December 2023. https://en.wikipedia.org/wiki/COVID-19_pandemic_in_Toronto.
- Consultative Committee on Space Data Systems. Audit and Certification of Trustworthy Digital Repositories – Recommended Practice – CCSDS 652.0-M-1. September 2011. http://public.ccsds.org/publications/archive/652x0m1.pdf. Accessed 21 September 2011.
- SP Journals. “Welcome to Scholars Portal.” https://web.archive.org/web/20110514013912/http://journals1.scholarsportal.info/discuss.xqy. Accessed 14 December 2024.
- Environment Canada. Atmospheric Hazards – Ontario Region. Environment Canada and Emergency Management Ontario, 22 December 2010. https://web.archive.org/web/20120120200739/http://ontario.hazards.ca/intro-e.html accessed 27 June 2022.
- Natural Resources Canada. “Background on Earthquakes in Eastern Canada.” Earthquake Zones in Eastern Canada. Natural Resources Canada, 2011. http://earthquakescanada.nrcan.gc.ca/zones/eastcan-eng.php#SGLSZ. Accessed 8 February 2012.
- University of Toronto Police. Annual Report 2003. University of Toronto Police St. George Campus, 2003. https://www.campussafety.utoronto.ca/_files/ugd/18f41b_297f54947cb74b928a54e212750aa694.pdf Accessed 27 June 2022.
- UTL Emergency Procedures Manual.
Review Cycle #
Ongoing